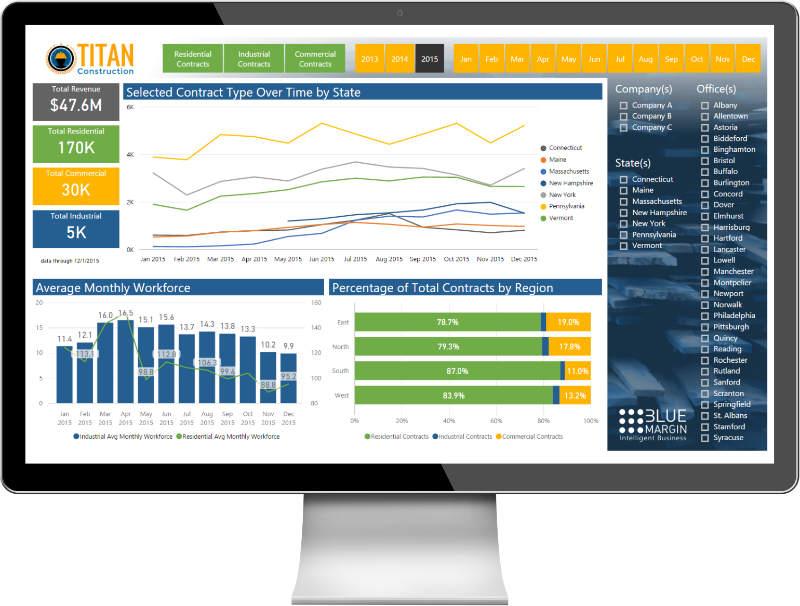
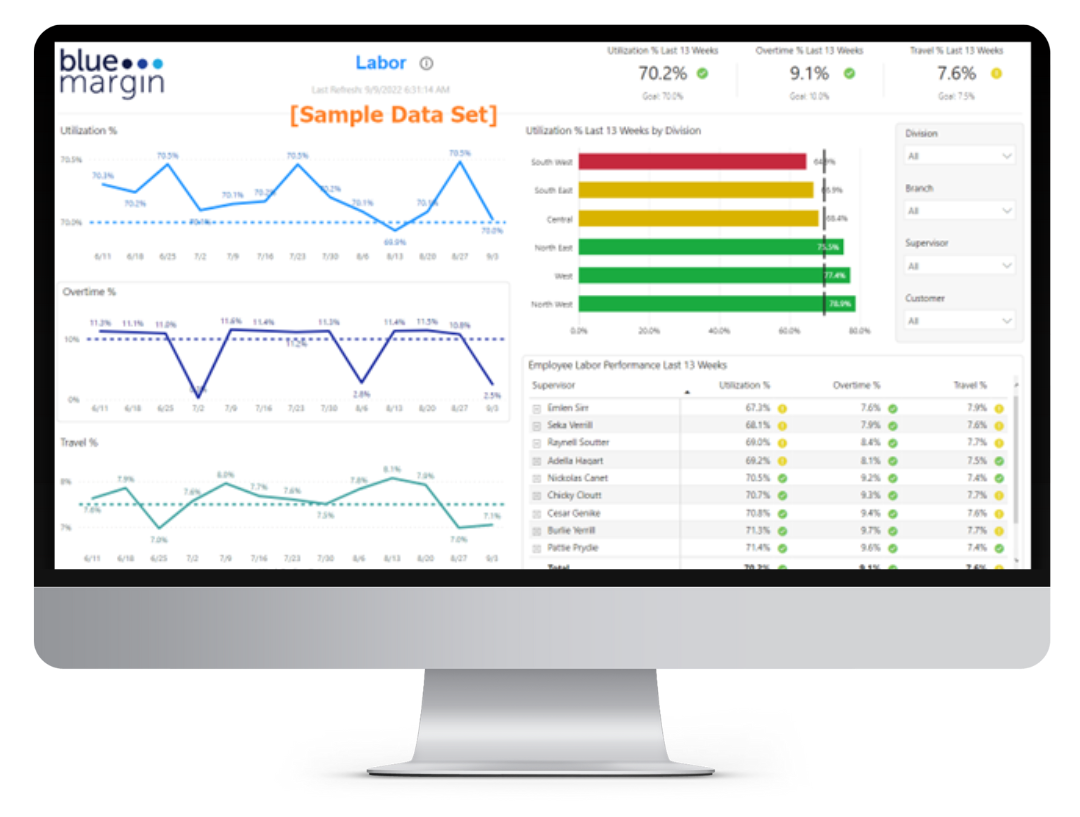
Understanding PE Buy-and-Build Success Factors
Reliable buy-and-build strategies that compete in the crowded private equity space need to be focused, intentional plans that involve multiple acquisitions of smaller—often under-performing—companies.
While many factors determine success over the course of the buy-and-build cycle, the potential to realize multiple arbitrage begins with the underlying strength of the platform company—and the leverage this gives general partners when seeking lower-multiple deals. If the platform company has the systems for efficient integration, GPs can more confidently pursue under-performing targets and their reduced acquisition multiples, securing a key component in the arbitrage strategy.
With efficient integration, performance of the acquired bolt-on can more quickly rise to the level of the already successful platform company. Conversely, inefficient integration not only means continued under-performance and lower multiples for bolt-ons, but also a likely drag-down in performance and value of the platform company.

The Value and Role of Data in Private Equity
One of the most critical (and perennially frustrating) elements of integration is data, and the ability to clearly assess performance in aggregate—and in comparison—across business units. Cobbling together reports from disparate systems, or holding out until software integrations can be completed, adds risk to acquiring under-performing assets. Flying blind can lead to reactive adjustments, unintended consequences, and a revolving door for the management team. Conversely, good private equity data intelligence allows add-ons to continue operating from day-one without disruption.
Making the case for the importance of data, Boston Consulting Group, in an article titled “Creating Value in Private Equity with Advanced Data and Analytics,” warns “companies that choose not to use data to create value risk hastening their own obsolescence or, at the very least, losing competitive advantage.”
Integrating disparate data from acquisitions can seem overwhelming, but it doesn’t have to be. As outlined in previous private equity data intelligence articles, investors need the ability to access near real-time performance data across the portfolio to accurately address and overcome barriers to growth.
The Modern Data Platform
Enter Microsoft Fabric*. Fabric seamlessly pulls together known tools (such as lakehouses, data lakes, and Power BI) to store, model, and report on your data from a single location. This platform supports efficient bolt-on integration by providing PE firms the following benefits and advantages:
- Data sources that are quickly and easily incorporated, with no requirement to extensively change existing processes and structures (learn more about the speed of integration with data lakes)
- A flexible data platform that adapts to new reporting requirements
- Near-term ROI through agile implementation that delivers actionable reports early and often
- A strong foundation for generative AI and natural language query
PE Buy-and-Build Success Factors Takeaway
This modern data platform gives GPs a key advantage in competitive markets. By allowing strong platform companies to efficiently integrate under-performing bolt-ons, lower-multiple acquisitions can be pursued, and the groundwork for successful arbitrage is laid.
*Even though Microsoft Fabric is still in preview, we can prepare your data for the transition now. Let us do the heavy lifting of consolidating your data into a data lake for easy access. Better yet, let us work with you as your fractional data team to transform your data into value-add reporting. Contact us today to get started.